
Generative AI and speech synthesis now make it possible for systems to act as proxies on users' behalf. ProxyMe is a VR prototype that combines avatar embodiment, voice cloning, and AI-mediated speech to explore situations where AI-modified output feels like part of one's own expression. This raises questions about how delegation and steerability affect perceived agency, authorship, and self-identification.
-
Is it Me? Toward Self-Extension to Al Avatars in Virtual Reality
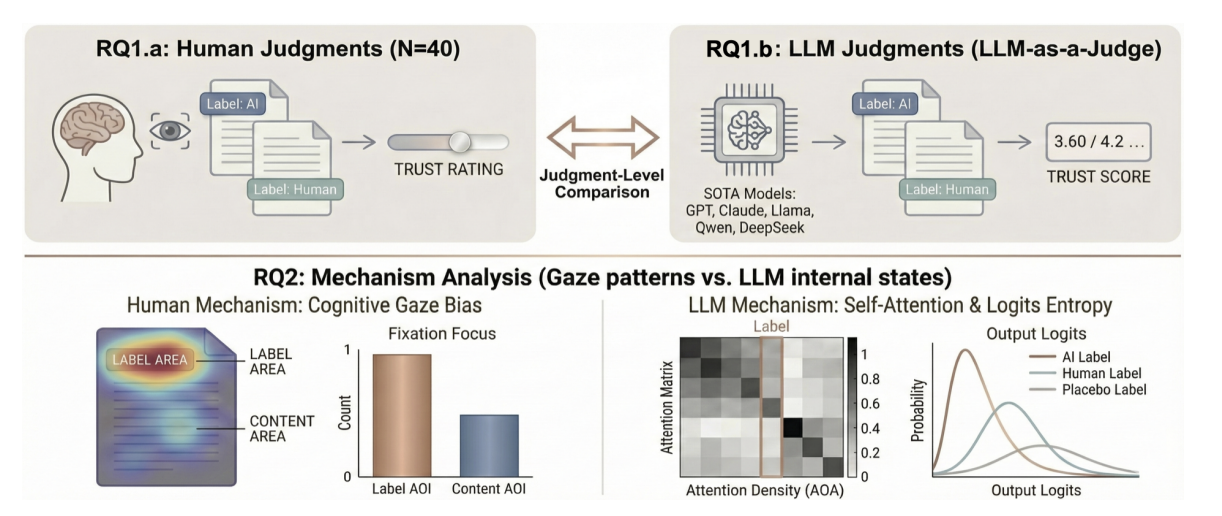
We investigate how AI assistance shapes human confidence, cognitive load, and trust, using behavioral signals like eye tracking to model these effects. Users and models alike are sensitive to contextual cues such as AI reliability and correctness, which alter how gaze patterns map to internal states. Trust judgments are also systematically skewed by surface cues like source labels and reasoning rationales, biasing both humans and LLMs toward miscalibrated assessments.
-
Label Effects: Shared Heuristic Reliance in Trust Assessment by Humans and LLM-as-a-Judge
-
Seeing the Reasoning: How LLM Rationales Influence User Trust and Decision-Making in Factual Verification
-
Eyes Can't Always Tell: Fusing Eye Tracking and User Priors for User Modeling under AI Advice Conditions

Chatbots are increasingly deployed for digital psychotherapy and personal health information access. Most current systems rely on rigid rule-based designs, while LLM-based alternatives offer flexibility but lack controllability and explainability in high-stakes contexts. This work examines how behavioral and physiological signals relate to trust in health-focused interfaces, and how LLMs can be better aligned to expert-crafted therapeutic strategies.
-
Understanding trust toward human versus AI-generated health information through behavioral and physiological sensing
-
Script-Strategy Aligned Generation: Aligning LLMs with Expert-Crafted Dialogue Scripts and Therapeutic Strategies for Psychotherapy
-
Rethinking the Alignment of Psychotherapy Dialogue Generation with Motivational Interviewing Strategies
-
From Aligned Language Models to Trusted User Interfaces: Explainable Health Intervention and Transparent Health Information Seeking

Dark patterns are deceptive interface designs that manipulate user decisions, yet most research focuses on visual modalities. We investigate the manipulative potential of haptic feedback, which we term Dark Haptics. A controlled study showed that alarming vibrotactile feedback could pressure participants into foregoing their privacy, laying groundwork for understanding and mitigating manipulative multisensory design.
-
Multi-sensory Dark Patterns
-
Demonstrating Dark Haptics Scenarios for Future XR Advertising
-
Dark Haptics: Exploring Manipulative Haptic Design in Mobile User Interfaces

Virtual agents typically lack the tactile qualities of human contact, making artificial biosignals a candidate for richer social VR interactions. Using vibrotactile heartbeats and thermally-actuated body temperature, we ran a study (N=31) to examine how these signals influence personal space during VR encounters. Thermal feedback reduced objective interpersonal distance, while vibrotactile heartbeats increased both objective and subjective distance alongside heightened arousal and discomfort.
-
Haptic Biosignals Affect Proxemics Toward Virtual Reality Agents

Generative AI is producing media increasingly indistinguishable from human-made content, raising concerns about misinformation and disclosure obligations under emerging regulations like the EU AI Act. We ran participatory workshops with researchers, designers, and engineers to deconstruct Article 52 disclosure requirements using the 5W1H framework. The result is a set of 149 questions across five themes that can help inform legal interpretation and human-centered AI disclosure research.
-
Full Disclosure, Less Trust? How the Level of Detail about AI Use in News Writing Affects Readers' Trust
-
More Human or More AI? Visualizing Human–AI Collaboration Disclosures in Journalistic News Production
-
Understanding AI Disclosure Needs for News Production and Journalism
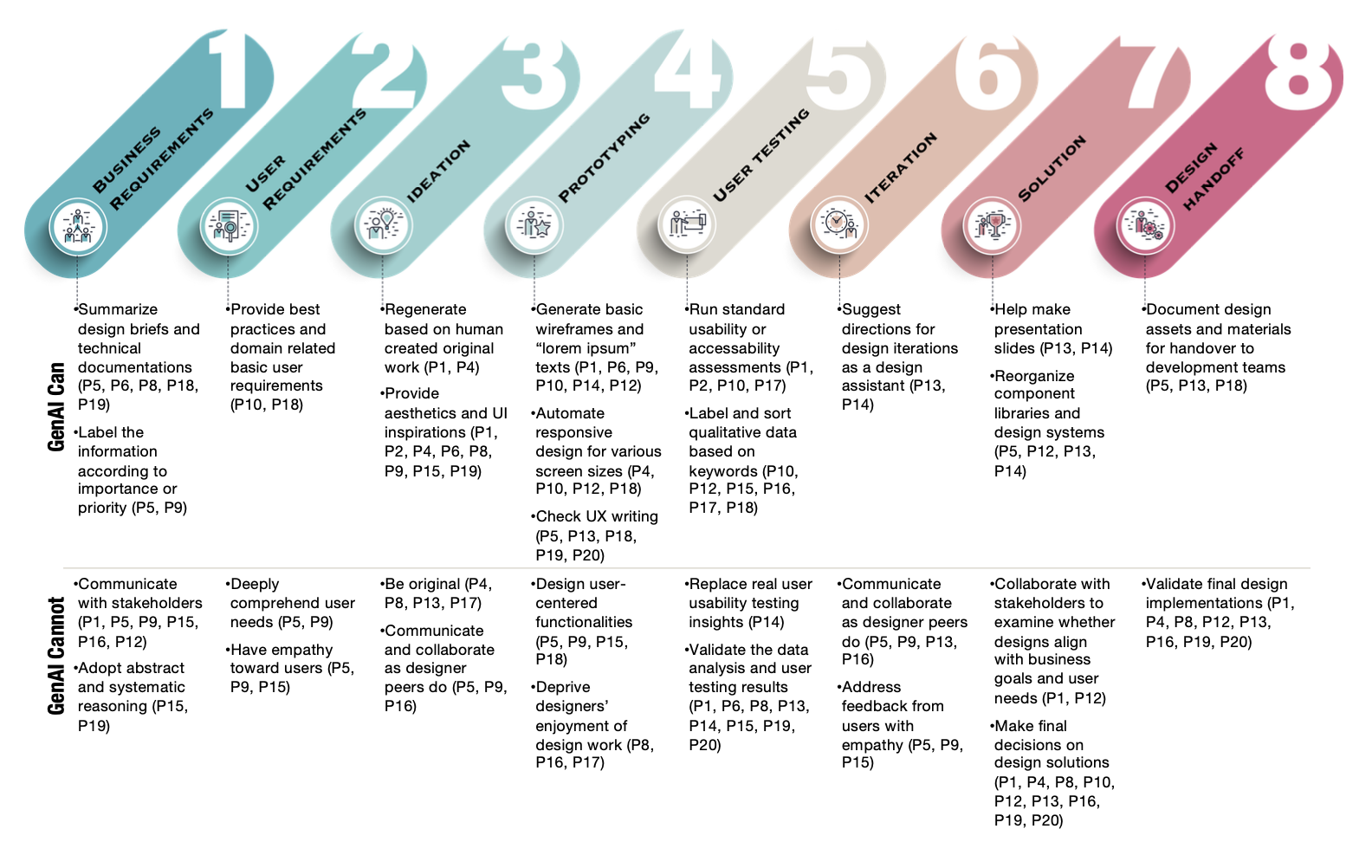
We interviewed 20 UX designers to examine how GenAI is reshaping professional practice across company types and experience levels. Experienced designers view GenAI as assistive, treating creativity, empathy, and agency as irreplaceable human qualities. Concerns about skill degradation, job replacement, and creativity exhaustion were more pronounced among junior designers.
-
Vibe Coding for Product Design: Understanding Product Team Members' Perceptions of AI-Assisted Design and Development
-
The Future of Work is Blended, Not Hybrid
-
User Experience Design Professionals' Perceptions of Generative Artificial Intelligence

Virtual co-embodiment lets two users share one avatar in VR, but joint-action coordination can break the illusion of shared control. A study with 20 participant pairs investigated how vibrotactile haptic feedback and control distribution affect agency, co-presence, body ownership, and motion synchrony. Haptics reduced agency in free-choice tasks and synchrony patterns differed by task type, offering cautions for haptic design in co-embodied experiences.
-
ShareYourReality: Investigating Haptic Feedback and Agency in Virtual Avatar Co-embodiment

Measuring cardiac interoceptive accuracy (CIAcc) has wellbeing and diagnostic implications, yet how display modality and environment shape such measurement is unclear. We developed a cardiac recognition task that modifies displayed heart rate across Screen and VR conditions, using audio, visual, and combined modalities (N=50). Participants consistently underestimated their heart rate by up to 30%, and VR presence inversely correlated with interoceptive accuracy.

Sharing breathing signals can offer insight into hidden emotional states and support interpersonal communication during collaborative tasks. We designed BreatheWithMe, a prototype for real-time breath signal sharing through visual and vibrotactile modalities, and tested it with 15 pairs. Visual feedback was preferred, but neither modality significantly influenced breathing synchrony, and participants raised concerns about data exposure and social acceptability.
-
BreatheWithMe: Exploring Visual and Vibrotactile Displays for Social Breath Awareness during Colocated, Collaborative Tasks

We designed FeelTheNews, a prototype combining vibrotactile and thermal stimulation during news video watching, to explore whether haptics can influence affective responses. A study (N=20) found that haptic stimulation did not significantly affect valence or emotion intensity ratings, and no stimulation was more comfortable than stimulation conditions. Attention to news content appeared to override haptic sensations, and users valued agency over their own reactions.
-
FeelTheNews: Augmenting Affective Perceptions of News Videos with Thermal and Vibrotactile Stimulation
Non-verbal cues like heart rate and breathing are absent in social VR, making biosignal visualization a candidate substitute. Through surveys, context-mapping, and co-design, we developed four visualization styles and tested them (N=32) in a virtual jazz bar. Skeuomorphic representations best supported arousal inference, with perceptions varying by avatar relationships and entertainment context.
-
Understanding and Designing Avatar Biosignal Visualizations for Social Virtual Reality Entertainment
-
Social Virtual Reality Avatar Biosignal Animations as Availability Status Indicators

Fine-grained emotion labels for 360° VR video watching require techniques that account for varying viewing behavior without disrupting presence. We designed RCEA-360VR, evaluating two peripheral visualization techniques (HaloLight and DotSize) in a controlled study (N=32) without increasing workload or sickness. Resulting annotations were consistent with discrete within-VR ratings, and fused labels aligned well with intended stimuli.
-
Annotation Tool for Precise Emotion Ground Truth Label Acquisition While Watching 360-degree VR Videos
-
Investigating the Relationship between Momentary Emotion Self-reports and Head and Eye Movements in HMD-based 360° VR Video Watching
-
RCEA-360VR: Real-time, Continuous Emotion Annotation in 360° VR Videos for Collecting Precise Viewport-dependent Ground Truth Labels
-
CEAP-360VR: A Continuous Physiological and Behavioral Emotion Annotation Dataset for 360° Videos
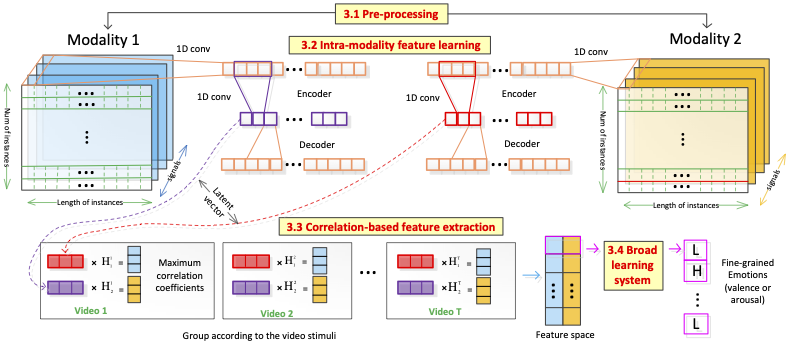
Recognizing emotions at a fine-grained level from wearable physiological signals requires methods that go beyond single-label classification per stimulus. CorrNet combines intra-instance and cross-instance features from signals like EDA and heart rate to predict valence and arousal per video segment. Results on both indoor desktop and outdoor mobile datasets show promising binary classification accuracy comparable across laboratory-grade and consumer wearable sensors.
-
CorrNet: Fine-Grained Emotion Recognition for Video Watching Using Wearable Physiological Sensors
-
Few-shot Learning for Fine-grained Emotion Recognition using Physiological Signals

Voice can convey emotion, but prosody is sometimes impaired situationally or medically. ThermalWear is a wearable on-chest thermal display that augments neutrally-spoken voice messages with warm or cool stimuli. A controlled study (N=12) showed that thermal stimulation can increase perceived arousal and modulate valence without causing discomfort, opening possibilities for voice assistant enhancement and support for individuals with prosody impairments.
-
ThermalWear: Exploring Wearable On-chest Thermal Displays to Augment Voice Messages with Affect
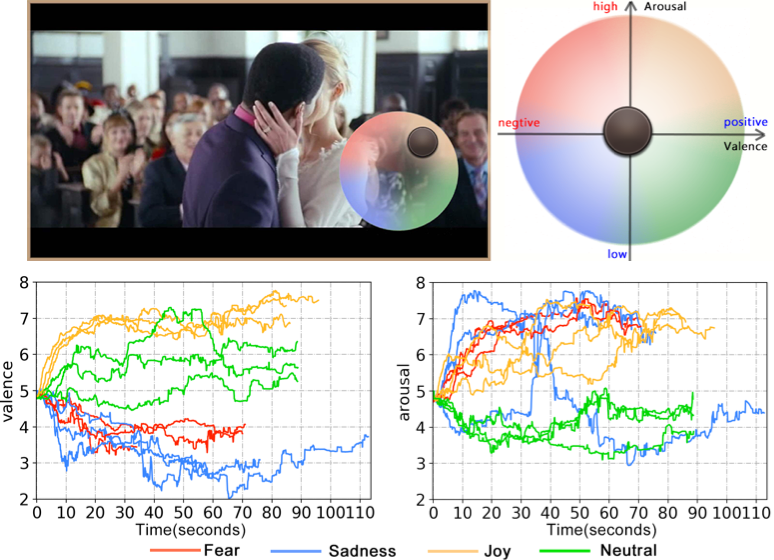
Collecting precise emotion labels during mobile video watching is difficult because existing annotation methods are either post-stimulus or desktop-only. We designed an RCEA technique for mobile contexts and validated it in indoor (N=12) and outdoor (N=20) studies using physiological measures, interaction logs, and workload reports. The technique was usable without increasing mental workload, and annotations aligned closely with intended emotional attributes of the stimuli.
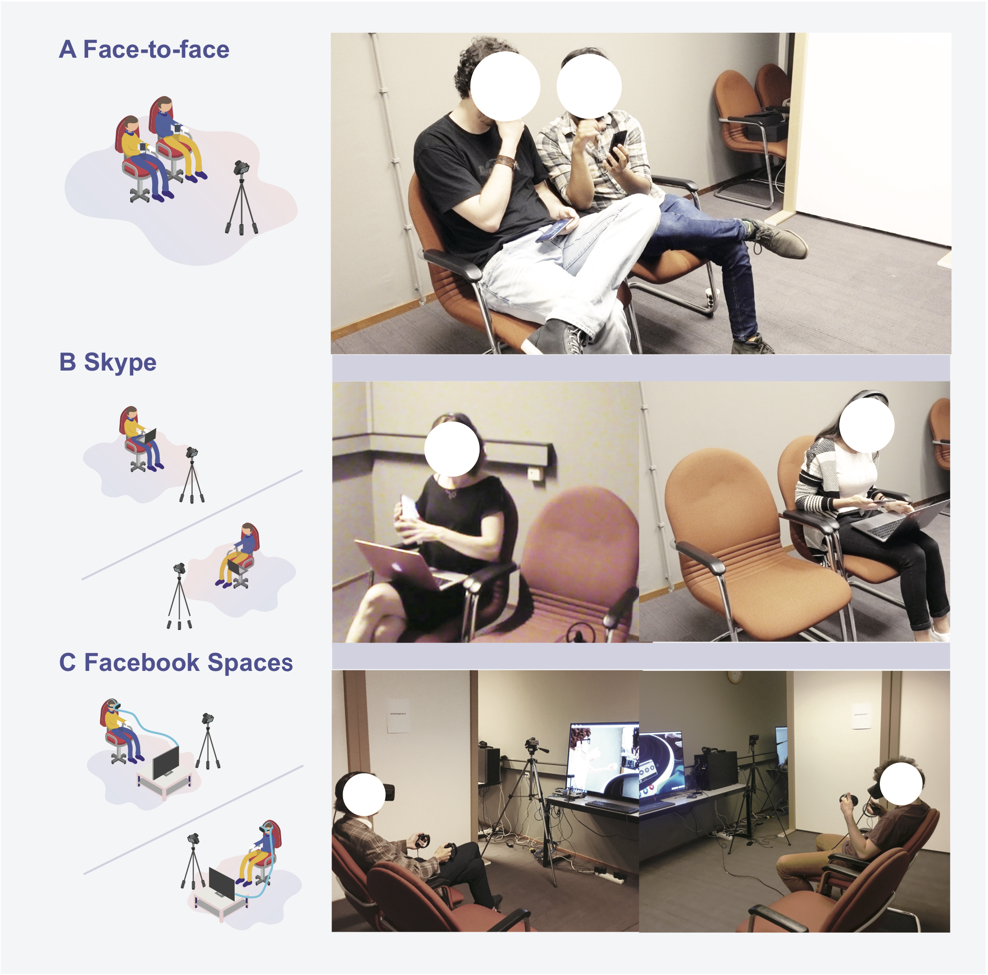
Online photo sharing lacks the richness of face-to-face interaction, but social VR may close this gap. Through context mapping, an expert session, and questionnaire development, we created a validated instrument to measure photo sharing experiences in immersive environments. A controlled study (N=26 pairs) comparing face-to-face, Skype, and Facebook Spaces found that social VR closely approximated face-to-face sharing.
-
Measuring and Understanding Photo Sharing Experiences in Social Virtual Reality
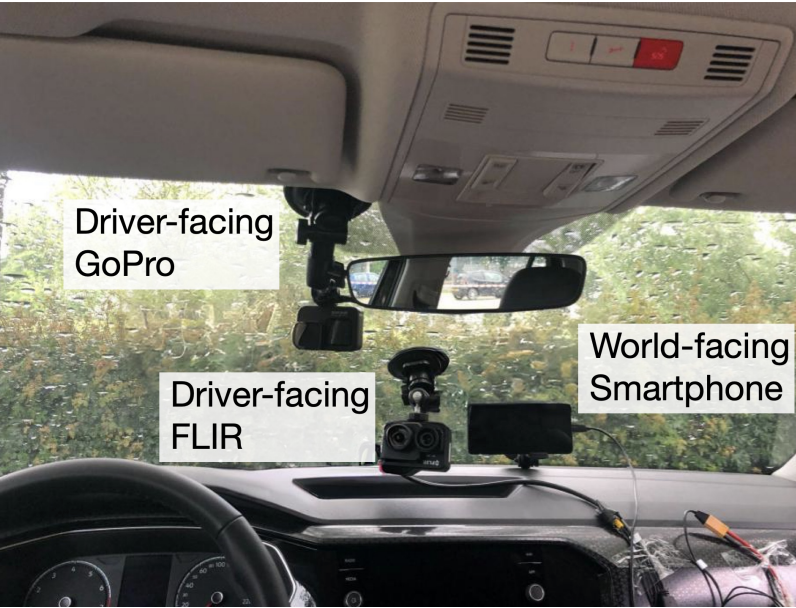
We designed a controlled outdoor driving circuit where drivers (N=27) encountered pedestrian confederates performing positive or non-positive non-verbal crossing actions. Drivers reported higher valence for positive actions and higher arousal for non-positive ones, with heart signals, skin conductance, and facial expressions all varying significantly between conditions. These findings inform the design of in-vehicle empathic interfaces that respond to drivers' affective states in real traffic scenarios.
-
Affective Driver-Pedestrian Interaction: Exploring Driver Affective Responses Toward Pedestrian Crossing Actions Using Camera and Physiological Sensors
-
From Video to Hybrid Simulator: Exploring Affective Responses toward Non-Verbal Pedestrian Crossing Actions using Camera and Physiological Sensors

We explored how ambient and peripheral light displays can support navigation and task resumption in cars without distracting drivers. Alongside this, we investigated the privacy implications of in-vehicle biometric sensing, finding that users hold nuanced concerns about identification accuracy in automotive contexts. This work connects to broader efforts in designing empathic interactions for automated vehicles, where physiological and behavioral signals can inform more responsive in-vehicle interfaces.
-
Peripheral Light Cues for In-Vehicle Task Resumption
-
NaviLight: Investigating Ambient Light Displays for Turn-by-Turn Navigation in Cars
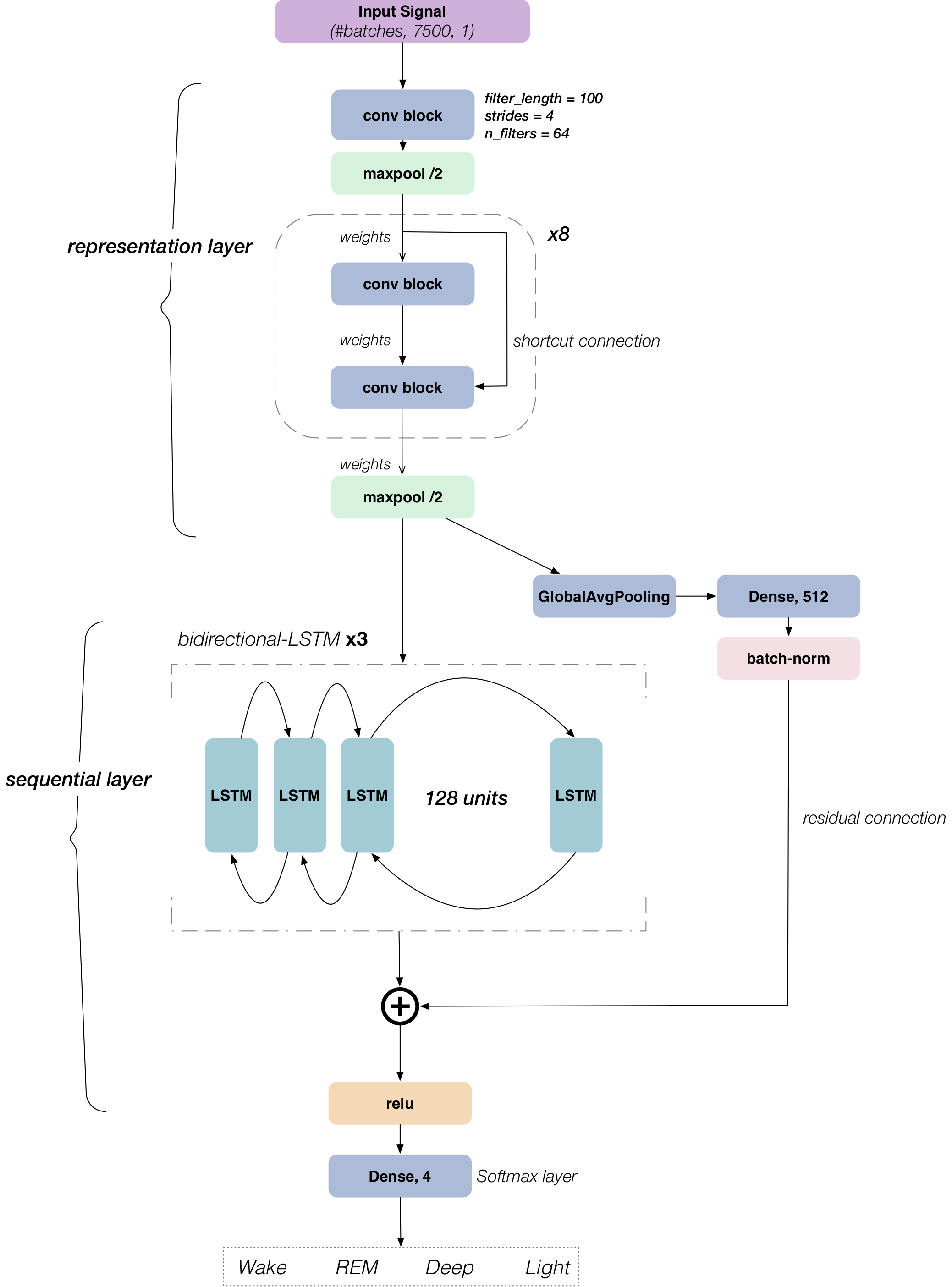
Existing sleep tracking methods are either obtrusive or low in accuracy. DeepSleep uses a ballistocardiographic signal from a pressure-sensitive sensor sheet, processed by a hybrid CNN-LSTM network with a two-phase training strategy. Classification accuracy reached 74–82% across multiple datasets, showing BCG signals are effective for long-term monitoring but not yet suited to medical diagnostics.
-
DeepSleep: A Ballistocardiographic Deep Learning Approach for Classifying Sleep Stages
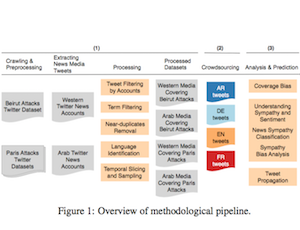
We examined coverage bias in Western and Arab media on Twitter following the 2015 Beirut and Paris attacks, crowdsourcing sympathy and sentiment labels for 2,390 tweets across four languages. A regression model characterized sympathy, and a deep CNN predicted it from tweet content. Western media showed less sympathy overall, and sympathetic tweets did not propagate any further than others.
-
Measuring, Understanding, and Classifying News Media Sympathy on Twitter after Crisis Events

Face2Emoji uses facial expression recognition to filter emoji by emotion category, addressing the difficulty of navigating large emoji libraries. We crowdsourced emotion labels for 202 emojis across 308 visitors and found they map reliably to seven basic emotion categories. Early CNN experiments achieved 65% accuracy on the FER-2013 dataset, with plans for usability testing.

In Lebanon, missing street signs, a poor road network, and a non-standardized addressing system challenge even technology-literate users. Through interviews (N=12) and a web survey (N=85), we examined how these users navigate using digital mapping tools and WhatsApp's location sharing. Many technical and cultural barriers persist, with social querying serving as the primary workaround.
Many e-cigarette users want to quit vaping, yet no feedback systems are tailored to their behavior. A web survey (N=249) showed that 46% of users want to quit altogether, and that trackable behavioral feedback can support this goal. VapeTracker is an early prototype that attaches to any e-cigarette device to track vaping activity using sensors, with ambient feedback mechanisms under exploration.

At Telekom Innovation Labs, we conducted three controlled studies using the Around Device Interaction paradigm with magnet-based 3D gestures. The studies examined the usability and security of magnet-based air signature authentication, as well as playful applications for music composition and gaming on mobile devices.

We investigated whether NFC-enabled mobile games could increase social interaction among strangers in public waiting spaces. A study compared an NFC version using a shared physical tag display with a touchscreen-only version of a collaborative pervasive game. NFC interaction offered distinct social benefits, and findings inform design of technology-mediated play in urban spaces.
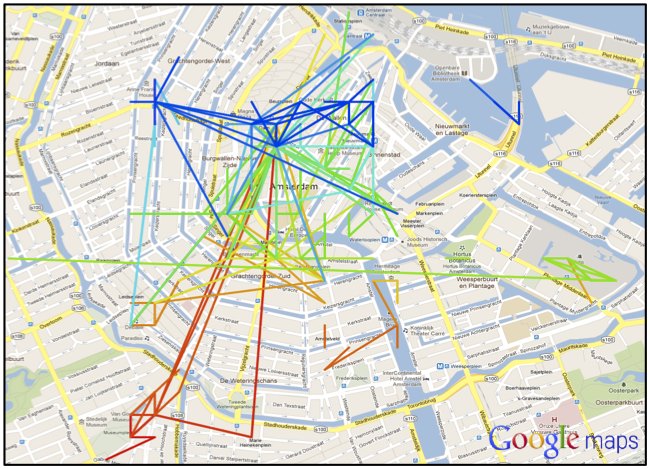
Most route planning tools optimize for speed, but pedestrians often prefer to explore. We designed a route recommendation system that uses geotagged Flickr photos and sequence alignment to compute non-efficiency-driven routes through Amsterdam. The system surfaces locally meaningful, scenic paths rather than shortest routes between two points.
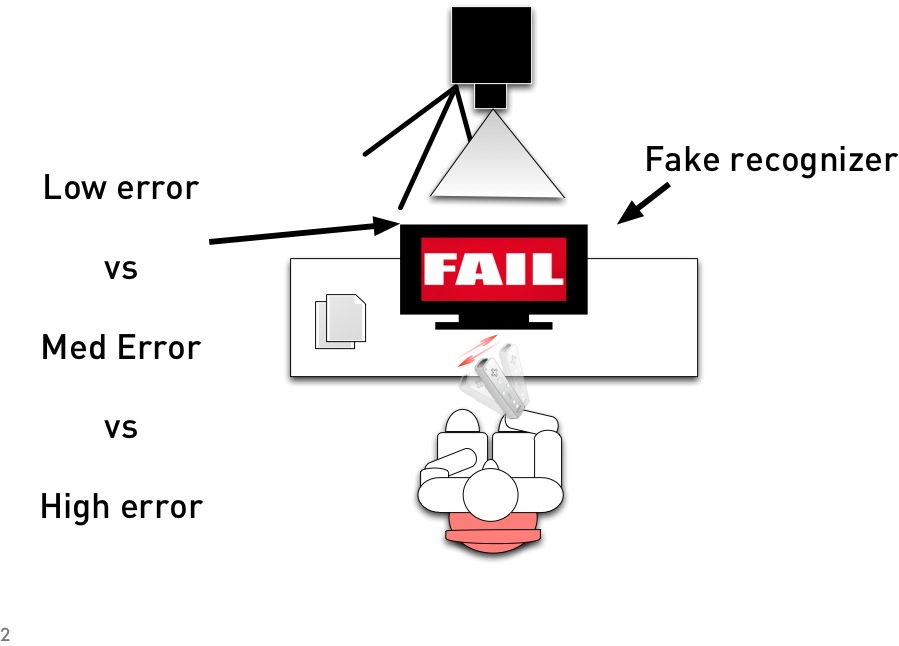
We investigated how recognition errors affect the usability and user experience of device-based 3D gesture interaction. A controlled study at Nokia Research compared mimetic and alphabet-based gesture sets under varying error conditions. The work received a Best Student Paper Award at ICMI 2012.

Location-aware multimedia messaging raises questions about what factors matter most to users creating such messages. Using the Graffiquity prototype as a probe, we ran a 2-week diary study to examine this messaging behavior in context. Findings informed design considerations for contextual, playful location-based communication systems.